
2日目の1限目は、理化学研究所 革新知能統合センター センター長・東京大学教授 杉山将先生の講義です。「人工知能研究のこれまでとこれから」と題して、人工知能(AI)についてお話しいただきます。

人工知能研究は、①AI技術の開発、②AIを使った科学研究、③AIによる社会課題の解決、④AIの倫理的・法的課題への対応、⑤AI人材の育成の五つの柱があるそうです。杉山先生は、「学校で学ぶ様々な学問が役立ってくる」と前置きをした上で、AIの基礎から最新の動向までわかりやすく説明してくださいました。
情報科学分野におけるAI技術の一分野を指す用語である「機械学習」の定義から始まり、機械学習には大きく分けて「教師付き学習」「教師なし学習」「強化学習」の三種類あること、その中で一番応用されてきたものは教師付き学習であったことなどを紹介いただいた後、メインテーマである「教師付き分類」の説明に入っていきました。
「一枚の画像は一つの点として表されます。機械学習では点を分ける直線を探します」と、杉山先生。
画像が点?いきなり何をおっしゃるか!?塾生の頭にはたくさんのクエスチョンマークが浮かんでいた事でしょう。それもそのはず、機械学習をきちんと理解するには高校以降の数学が必要になってきます。中学生の塾生にそこをどう説明していくのか、自分自身も関連分野を研究しているため、非常に興味深いものでした。
講義の途中で、質問タイムを挟みます。さすがは塾生といったところで、「点として表現されるということがよくわからない」という、素直で、他の塾生にとっても非常に重要な質問や、予測誤差の説明の図の点の並びに注目した、機械学習の問題意識に迫る質問など、ここでは挙げきれないほどたくさんの質問が出てきましたが、先生は一つ一つ丁寧に回答してくださいました。
続いて、機械学習を実際に応用する際に直面する問題点にどう対処していくか、現在研究されている最新の情報の紹介に移ります。特に、直線分離できないこと、一つ一つのデータに対して付与される正解“ラベル”に“雑音”が含まれていること、ラベル付き訓練データが少ないこと…など三つの問題に対して、それぞれの解決手法が考えられているとのことでした。最先端の内容だけあって専門用語が多く飛び交う中、塾生は先生に言葉の意味を確認しつつ真剣に理解しようとしていました。
先生は最後に「機械学習の研究を行うには多くのスキルが必要になるので、専門分野は一つだけではなく二つあるといいと思います。幅広く勉強して一つの専門と他の副専門を持ってください。」と話し、講義を締めくくりました。
一人で複数の専門性を持つことは難しいかもしれませんが、少なくとも他分野を理解し、共同で研究をしてくことが重要な時代になっています。先生の講義をきっかけに幅広く勉強することの重要性に気付いてもらえると嬉しいです。
【記事:野々宮 悠太(6期生)】
講義動画
※この講義の動画公開は終了しました。(23.8.28)
【塾生からの質問1】
スーパーコンピューターも使ってAIについての研究を進めているとおっしゃっていましたが、スーパーコンピューターはどのように使っているのでしょうか?
倫理の問題もあり、難しいところが多いと思うのですが、今AI は医療の分野でどれくらい普及しているのでしょうか?
AIは人間と共に学ぶということをおっしゃっていました。AIが人間の知能を上回るということはできると思うのですが、それでも共存ができる(乗っ取られない)と考えているのはどうしてですか?
今後、AIがさらに広まる分野はどこだと考えていますか?
【質問1に対する先生のお返事】
今のAIには人間が手で調整しないといけないパラメータがたくさんあります.例えば,カーネル法の話をしたところで,2次元のデータを3次元の特徴空間に変換しましたが,特徴空間は3次元である必要はなく,4次元でも5次元でも構いません.でも,その次元数の選び方によってAIの性能が上がったり下がったりしますので,次元数をうまく決めてやる必要があります.このような場面では,色々なパラメータに対して実際に学習をしてみて,一番うまくいくものを選びます.このとき,スーパーコンピュータがあれば,そのような計算を並列に一気に実行できますので,超高速に学習できます.
日本では,法律で医療診断はあくまでも人間の医師しか行えないことになっています.ですので,いまのところ,AIはあくまでも医療診断の補助をするだけなのですが,医療診断の補助をする機械は医療機器として国の認可を取る必要があります.この認可を取るためには一般に何年もがかかりますので,実のところ高度なAIを使った医療機器は,まだそれほど普及しています.でも,次々と新しい技術が生まれていますので,近いうちにどんどん普及してくと思います.
いまのAIはあくまでもコンピュータのプログラムですので,人間がプログラムを実行しなければ何も起こりません.ですので,人間自身が,他の人を乗っ取るような悪いAIをわざわざ作らない限りは,AIが人を乗っ取るということは起こらないと思います.
これまではAIは主にインターネットの世界で普及してきましたが,これからは,お店,街の中,学校など,実世界で使われるようになってくると思います.
【塾生からの質問2】
深層学習の部分について質問です。深層学習では非線形変換を何度も繰り返し徐々に複雑な関数を表現するとおっしゃっていましたが、返還を繰り返す中で、入力層から入ったデータと出力層から出るデータが変わってしまうことはないのですか。
【質問2に対する先生のお返事】
「データが変わる」が何を指しているかはっきりとわかりませんが,非線形変換を一つ決めれば,同じ入力に対しては同じ出力が出てきます.そういう意味では,データは変わらないということになります(答えになっていますでしょうか).
【塾生からの質問3】
今日は大変興味深い講義をありがとうございました。質問なのですが、
AIへの教育はまるで人間のようだと感じたのですが、先生は人間とAIの違いはどんなところにあると考えていらっしゃいますか。
また、AI側がミスをすることはあるのですか。
【質問3に対する先生のお返事】
AIがどんどん進化していくと,その違いはだんだんがわからなくなって来ると思います.これまでは,AIは人間のように感情を持たない,あるいは,AIにはクリエイティブなことができないと言われていましたが,最近のAIはそういたことも徐々にできるようになりつつありますので,将来は人間もAIもあまり変わらなくなるのかもしれません.
そもそもAIが必ず正しい答えを出す保証は全くありませんので,AIもミスをします.ですので,例えば自動運転車が常に安全だと保証することはできません.AIを使う人間は,そのことを十分に意識しておく必要がありますね.
【塾生からの質問4】
今日の授業、とても面白かったです。おりがとうございました。質問お願いします。Q1人工知能はこれからも人間に支配?されて人間のためにあるものとなるのですか?一つの物、ひとつの生き物として生きる(生きるという表現が少しあいまいです。)ことはないと思いますか?Q2次元の話で、一次元は点、二次元は線、三次元は立体というのはわかるのですが、10次元や100次元などはどのようにとらえたらいいですか?Q3ゲーム等で人工知能と対戦するときなどの人工知能のレベル(強さ)は、どうやって分けているまですか?(常に最善手をしていたら強さが一番強いとおもいました。)
【質問4に対する先生のお返事】
Q1:AIを一つの生き物と捉えるのは面白い考え方ですね.AIの性能がどんどん向上していくと,人間から見てAIが生き物のように自律して動いているように見えるようになると思います.そうすると,AIは一つの生き物だとみなしても良いかもしれませんね.
Q2:1次元の点はxという一つの変数で表現できて,2次元の点は(x,y)という2つの変数で,3次元の点は(x,y,z)の3つの変数で表現できます.私達は3次元の世界で生きていますので,3次元までしかものを見ることができませんが,4次元以上の点も同じように表現できます.例えば,100次元の点は,(x1,x2,...,x100)という100個の変数で表現できます.4次元以上の点は直接見ることができませんので想像しにくいですが,数学的には3次元でも100次元でも同じように扱えます.なお,大学の数学では「無限次元」の空間を学びます.
Q3:常に最善手を指すゲームAIができてしまうと,強すぎてゲームをしても面白く無いんですよね.そうならないように,わざと少し間違えるようにプログラムしたりします.どのように間違えると人間から見て自然か,あるいは,ゲームとして面白くなるかを研究している人もいます.
【塾生からの質問5】
学んだ情報などをうまく区別できないときに次元を変えてうまく区別できるようにする深層学習というものがあったとおもいます。深層学習でカーネル関数を何回か使って次元を何度もかえるとおっしゃっていましたが、それは1度で次元を変えるのと何が違うのか、また、中間層がある必要性がわかりません。中間層をぬかすことはできないのかを教えていただきたいです。
【質問5に対する先生のお返事】
大変いい質問です.おっしゃるとおり,複数回の変換を一度の変換で表現することは可能です.しかし,たとえそうであっても,わざと変換を複数回に分けて学習することで,なぜか学習がうまくいくというのが今の深層学習なのです.実のところ,まだその原理は数学的に完全には解明されていません.最新の研究成果で,少なくとも2回の変換に分けると,学習の性能が飛躍的に向上することが証明されつつあります.直感的には,1回目の変換でデータのどこに注目するかを学習して,2回目の変換で関数を学習するというイメージです.こうすることによって,1回で直接関数を学習するよりも性能が上がります.
【塾生からの質問6】
雑音遷移補正についての質問です。雑音遷移行列で、ラベルが変わる確率は、どのようにして分かるのですか。
【質問6に対する先生のお返事】
これはまさにいま研究が進んでいるテーマです.まずは,雑音の無いデータがいくつかあれば,雑音遷移行列をきちんと推定できることが証明されています.一方,雑音のあるデータしかない場合は,そのままでは雑音遷移行列を推定することは不可能だということが証明されています.しかし,ラベルが変わる確率はそれほど大きくないといった,実際に成り立っていそうなちょっとした制約を加えることによって,雑音遷移行列がうまく推定できるようになりつつあります.
【塾生からの質問7】
いくつか質問があります。
一つめ、教師なし学習の応用例として挙げられていた画像生成というものについてなんですが、画像生成の前段階のデータを与える時に、特定の人に似た画像データを与えて画像生成させると、その人に似た人の顔が生成されるんですか?
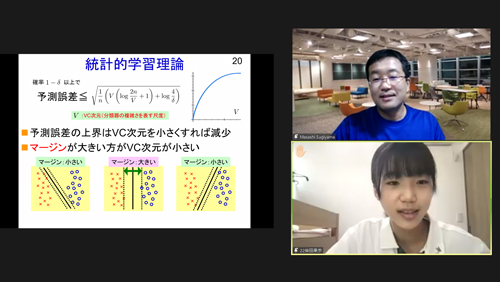
二つめ、統計的学習理論の時に、VC次元を小さくすれば予測誤差の上界は減少すると講義の中でおっしゃっていました。スライドにはVC次元は、分類器の複雑さを表す数値とにはかいてあるのですが、分類器が複雑とはどういうことですか?
三つめ、これは直接講義と関わりがないんですけど、AIについて勉強するにあたって、いい本(新書とか参考書)など何かある場合は教えていただきたいです。
【質問7に対する先生のお返事】
1.そうですね.どんなデータを使って学習するかによって,生成される画像が大きく変わります.その特性を利用して,例えば,日本人の画像だけを使って学習すると,日本人っぽい顔画像を作ることができます.
2.本当は数学的に定義される概念ですので,言葉で書くと曖昧になってしまうのですが,分類器がデータの色々な分け方を表現できるとき,その分類器は「複雑」だと言います.マージンが大きいとき,そのマージンの中で境界線の角度を変えてもデータの分け方は変わりません.なので,マージンが大きいは分類器は「単純」になり,VC次元が小さくなります.
3.具体的な教科書を示すのは難しいのですが,機械学習をきちんと勉強しようと思うと,ベクトル,行列,微分,積分,確率,統計など,高校卒業レベルくらいの数学が必要になります.私も何冊か教科書を書いていますが,そういう数学が大体わかっている前提の内容になっています.一方,そういった数学をできるだけ使わず,Pythonなどのプログラム言語を使って深層学習のプログラムを作ってみようという教科書がたくさん出ています.これらは,機械学習の原理を勉強するには不向きですが,実際にプログラムを作って動かすことができますので,楽しみながら機械学習の考え方を学ぶのに向いているかと思います.
【塾生からの質問8】
先日は、質問を答えていただきありがとうございました。先生に質問が3つあります。
AI に個人情報を使うことなく、学習させるために、~さんは~と言っていますがあなたは指示しますか?という方法でアンケートを集めると言っていましたが、その~さんは空想上の人物を使うのですか?それとも、著名人の情報や、その研究を行う本人の情報を活用するのですか?
複数のAIをひとつの端末に入れることで
AIがお互いの制御を切ってしまい、人間がAIを押さえきれなくなる可能性はありませんか?
AIによって、職業を失った人はどのようなことを行えますか?
【質問8に対する先生のお返事】
授業での例では,「~さん」は具体的に実在する人を想定しています.分類器の中では,一人の人は一つの点として表現されます(講義で出てきた猫や犬の例と同じ考え方です).「~さん」の例では,その点がYesなのかNoなのかというラベルは直接集めないという話をしていることに対応しますが,その点(人)そのものは存在することを仮定しています.空想上の人ですとその点は存在しないことになってしまいますが,著名人であれば,「点」の情報がわかれば学習ができます.
今のAIはただのコンピュータのプログラムですので,人間が止められなくなることは原理的にありえないと思います.ただ,悪意を持った人が,他人を攻撃するようなプログラムを作ったとすると,問題が起こる可能性は十分にあります.結局は人間次第なのかもしれませんね.
例えば,手書きのアンケートをコンピュータに打ち込むという仕事は,AIによる文字認識を使うとかなり自動化できてしまいます.同時通訳も,AIでかなり代替できるようになってきました.一方,AIを使って新しいサービスを開発するとか,スマホを更に便利にするとか,AIがなかった時代には存在しなかった新しい仕事が次々と生まれています.一つの仕事にこだわらず,新しい仕事を積極的に探していくことが今後ますます重要になってくると思います.
理化学研究所 センター長/東京大学 教授
■研究業績
機械学習の基礎理論とアルゴリズム開発に従事
・非定常環境に対する機械学習技術の開発:Sugiyama, M. & Kawanabe, M. Machine Learning in Non-Stationary Environments: Introduction to Covariate Shift Adaptation, MIT Press, 2012.
・密度比推定に基づく汎用的なデータ解析技術の開発:Sugiyama, M., Suzuki, T., & Kanamori, T. Density Ratio Estimation in Machine Learning, Cambridge University Press, 2012.
・統計的強化学習技術の開発:Sugiyama, M. Statistical Reinforcement Learning: Modern Machine Learning Approaches, Chapman and Hall/CRC, 2015.
・弱教師付き学習技術の開発:Sugiyama, M., Bao, H., Ishida, T., Lu, N., Sakai, T., & Niu, G. Machine Learning from Weak Supervision: An Empirical Risk Minimization Approach, MIT Press, to appear.
■受賞歴
2007年 IBMファカルティ賞
2011年 情報処理学会長尾真記念特別賞
2012年 船井情報科学振興財団船井学術賞
2014年 科学技術分野の文部科学大臣表彰若手科学者賞
2017年 日本学士院学術奨励賞
2017年 日本学術振興会賞
2019年 KDDI財団KDDI Foundation Awards
2019年 Google AI for JapanグーグルAI重点研究賞
■著書
杉山 将.統計的機械学習:生成モデルに基づくパターン認識,オーム社, 2009.
杉山 将.イラストで学ぶ機械学習:最小二乗法による識別モデル学習を中心に,講談社, 2013.
井手 剛, 杉山 将.異常検知と変化検知,講談社, 2015.
杉山 将.機械学習のための確率と統計,講談社, 2015.